切换科目
重点科目
主要科目
次要科目
科数网
首页
刷题
学习
VIP会员
赞助
组卷
集合
教材
VIP
写作
游客,
登录
注册
在线学习
人工智能
旧版本
第一章 线性回归
超参数
最后
更新:
2025-02-17 14:19
查看:
135
次
纠错
评论(0)
课件
开VIP
超参数
超参数是用于控制训练不同方面的变量。以下是三个常见的超参数: 学习速率 批量大小 纪元 与之相反,参数是模型本身的一部分,例如权重和偏差。换句话说,超参数是您控制的值;参数是模型在训练期间计算的值。 ## 学习速率 学习率是您设置的浮点数,会影响模型收敛的速度。如果学习率过低,模型可能需要很长时间才能收敛。但是,如果学习速率过高,模型将永远不会收敛,而是在最小化损失的权重和偏差之间来回跳动。目标是选择一个学习速率,使其既不太高也不太低,以便模型快速收敛。 学习速率决定了在梯度下降过程的每一步中对权重和偏差进行的更改幅度。模型会将梯度乘以学习速率,以确定下一次迭代的模型参数(权重和偏差值)。在梯度下降的第三步中,向负斜率方向移动的“小量”是指学习速率。 旧模型参数与新模型参数之间的差异与损失函数的斜率成正比。例如,如果斜率较大,模型会迈出较大的步伐。如果小,则只需迈出小步。例如,如果梯度幅度为 2.5,学习率为 0.01,则模型将将参数更改 0.025。 理想的学习率有助于模型在合理的迭代次数内收敛。在图 21 中,损失曲线显示模型在前 20 次迭代中取得了显著改进,然后才开始收敛: 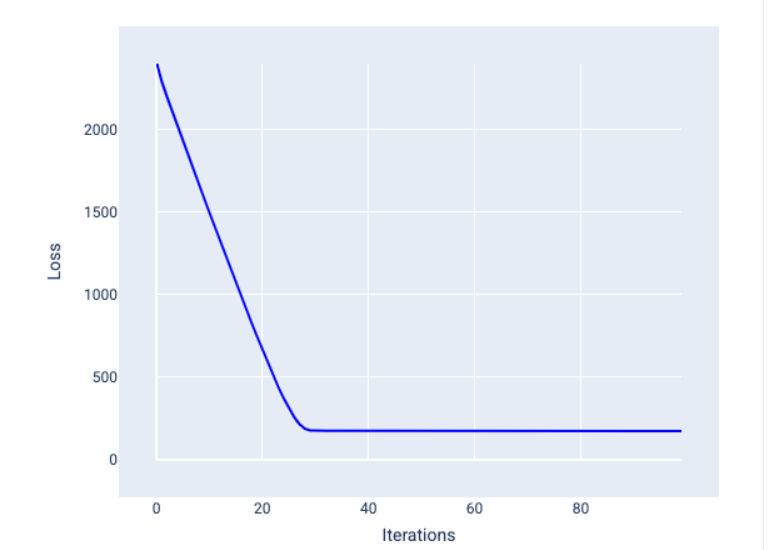 图 21. 损失图,显示使用快速收敛的学习率训练的模型。 相反,学习率过低可能会需要过多的迭代才能收敛。在图 22 中,损失曲线显示模型在每次迭代后仅会略有改进: 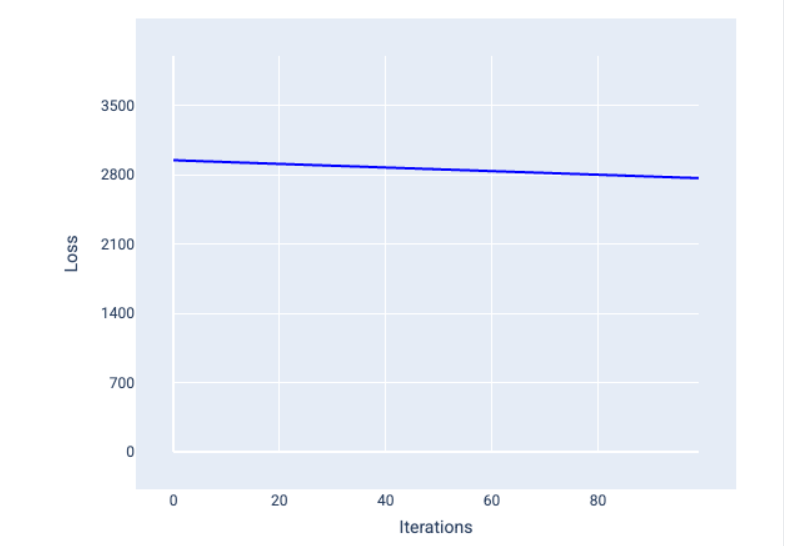 图 22. 损失图,显示使用较小学习速率训练的模型。 学习速率过高时,模型永远不会收敛,因为每次迭代都会导致损失出现波动或持续增加。在图 23 中,损失曲线显示模型在每次迭代后损失先减小后增大,而在图 24 中,损失在后续迭代中会增加: 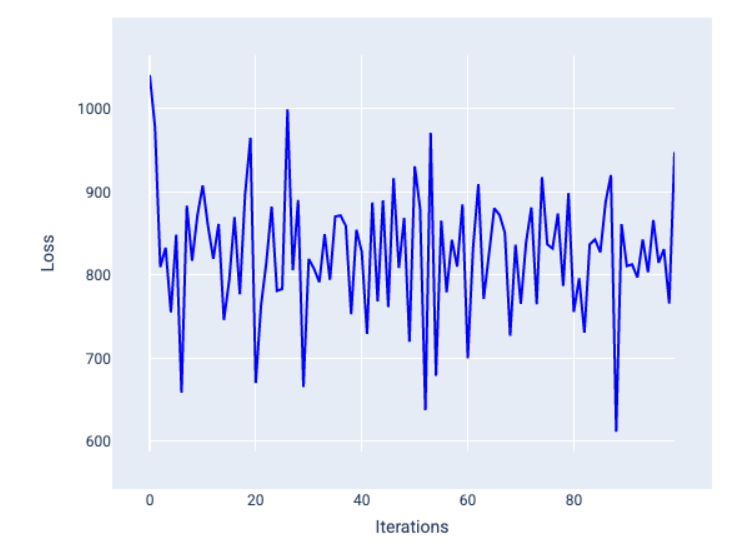 图 23. 损失图,显示使用过大学习率训练的模型,其中损失曲线会大幅波动,随着迭代次数的增加而上下波动。 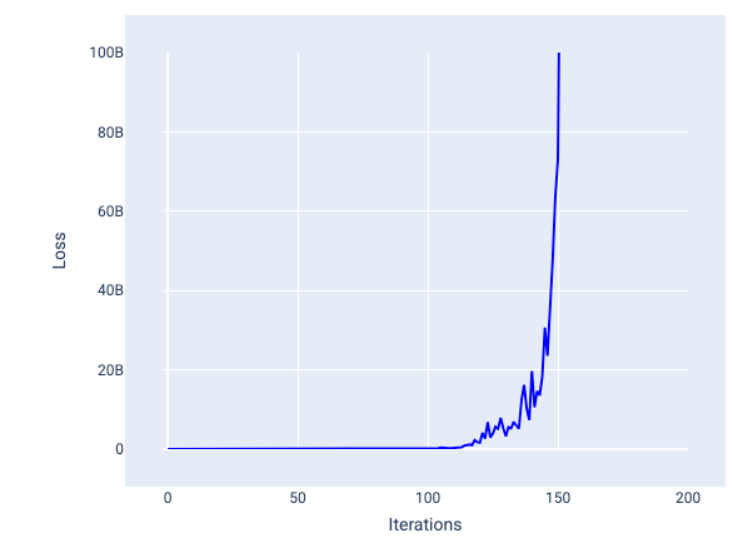 图 24. 损失图,显示使用过大学习速率训练的模型,其中损失曲线在后续迭代中急剧增加。 ## 批次大小 批处理大小是一个超参数,表示模型在更新权重和偏差之前处理的示例数量。您可能会认为,模型应先计算数据集中每个示例的损失,然后再更新权重和偏差。但是,如果数据集包含数十万甚至数百万个示例,使用完整批处理是不切实际的。 以下两种常用技术可在平均情况下获取正确的梯度,而无需在更新权重和偏差之前查看数据集中的每个示例,这两种技术分别是随机梯度下降和小批量随机梯度下降: 随机梯度下降法 (SGD):随机梯度下降法每次迭代只使用一个示例(批量大小为 1)。在足够的迭代次数下,SGD 会起作用,但噪声很大。“噪声”是指训练期间的变化,会导致在迭代过程中损失增加而不是减少。“随机”一词表示每个批次包含的一个示例是随机选择的。 请注意下图中,随着模型使用 SGD 更新其权重和偏差,损失如何略有波动,这可能会导致损失图表中出现噪声: 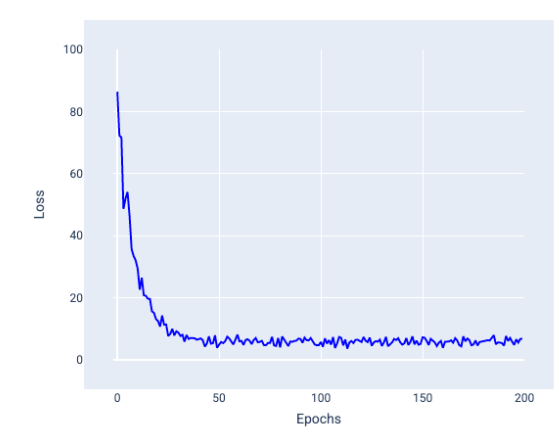 图 25. 使用随机梯度下降法 (SGD) 训练的模型,损失曲线中显示了噪声。 请注意,使用随机梯度下降法可能会在整个损失曲线中产生噪声,而不仅仅是在收敛附近。 小批次随机梯度下降法 (mini-batch SGD):小批次随机梯度下降法是全批次梯度下降法和 SGD 之间的折衷方案。对于 个数据点,批处理大小可以是任何大于 1 且小于 的数字。模型会随机选择每个批处理中包含的示例,对其梯度求平均值,然后每迭代一次更新权重和偏差。 确定每个批次的示例数量取决于数据集和可用的计算资源。一般来说,批量大小较小时,其行为类似于 SGD;批量大小较大时,其行为类似于全批梯度下降。 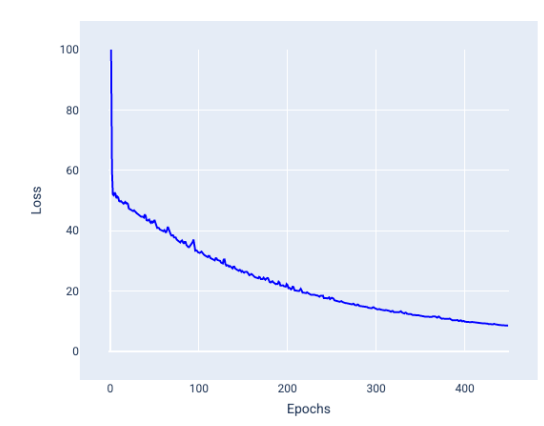 图 26. 使用小批量随机梯度下降法训练的模型。 在训练模型时,您可能会认为噪声是一种不良特征,应予以消除。不过,适当的噪声也未尝不可。在后续模块中,您将了解噪声如何帮助模型更好地泛化,以及如何在神经网络中找到最佳权重和偏差。 ## 周期数 在训练期间,一个周期表示模型已处理训练集中的每个示例一次。例如,假设训练集包含 1,000 个示例,小批量大小为 100 个示例,则模型需要 10 个iterations才能完成一个 epoch。 训练通常需要进行多次迭代。也就是说,系统需要多次处理训练集中的每个示例。 迭代次数是您在模型开始训练之前设置的超参数。在许多情况下,您需要进行实验,以确定模型需要多少个周期才能收敛。一般来说,训练周期越多,模型越好,但训练时间也越长。 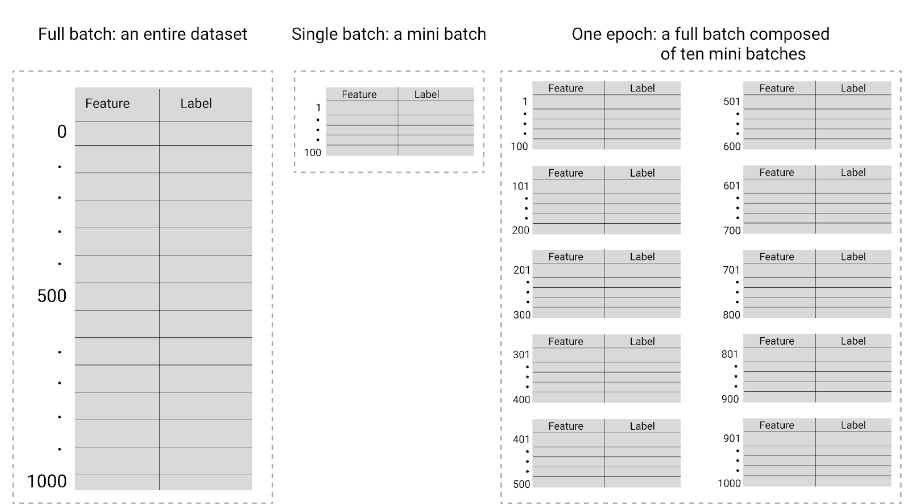 下表介绍了批处理大小和迭代次数与模型更新其参数的次数之间的关系。 批次类型 权重和偏差更新的时间 完整批次 模型查看数据集中的所有示例后,例如,如果数据集包含 1,000 个示例,并且模型训练了 20 个 epoch,则模型会更新权重和偏差 20 次,即每个 epoch 更新一次。 随机梯度下降法 模型查看数据集中的单个示例后。 例如,如果数据集包含 1,000 个示例,并且训练了 20 个 epoch,则模型会更新权重和偏差 2 万次。 小批量随机梯度下降法 模型查看每个批次中的示例后,例如,如果数据集包含 1,000 个示例,批处理大小为 100,并且模型训练 20 个 epoch,则模型会更新权重和偏差 200 次。
科数题库(单机版)
会议室预约系统(book)
今日还可看
0
篇 未注册用户每天查看4篇,
注册
用户每天8篇,
开通VIP
会员无限制查看。
免费注册
《高等数学》难点解析
高数教程
泰勒公式
切线与法线
切平面与法平面
驻点·拐点·极值点·零点
间断点
渐进线
瑕积分
欧拉方程
伯努利方程
Abel 收敛定理
偏导数的几何意义
偏导数的几何意义
梯度
数量场与向量场
多元函数极值
拉格朗日算子
通量与散度
环流量与旋度
格林公式
高斯公式
斯托克斯公式
三大公式比较
傅里叶级数
极坐标微元
点法式方程
变上限定积分
X型计算面积
Y型计算面积
微分的意义
渐近线
间断点
y''+py'+qy=f(x)方程
高斯
黎曼
傅里叶变换(复数)
拉普拉斯变换(复数)
《线性代数》难点解析
线代教程
近世代数对数学的整体思考
线性的意义
矩阵乘法(列视角)
矩阵乘法(行视角)
矩阵左乘
矩阵右乘
逆矩阵求解方程组
阶梯形矩阵的求法
方程组解的判定
四阶行列式的计算
线性变换的意义
线性空间
向量组的等价
线性空间的几何意义
基础解系的求法
施密特正交化
特征值与特征向量的意义
矩阵相似的几何意义
矩阵可对角化的理解
秩的意义(向量版)
秩的意义(方程版)
二次型的意义
《概率论与数理统计》难点解析
概率教程
置信区间与上a分位数
概率中的“取”与“放”
贝叶斯公式
全概率公式
泊松分布
指数分布
伽玛分布
二维密度图的意义
卷积的意义
相关系数的意义
k阶矩是与矩母函数
卡方分布的作用
单正态区间估计理解
假设检验理解
切比雪夫不等式
中心极限定理
上一篇:
梯度下降
下一篇:
没有了
本文对您是否有用?
有用
(
0
)
无用
(
0
)
赞助:
知乎 Mathhub
启明星
商务合作
赞助本站
科数网
是专业的数学网站,为您提供题库与教程 版权所有 禁止镜像
部分内容采用AI辅助生成,请注意识别
如果页面无法显示请联系 18155261033 或 983506039@qq.com