切换科目
重点科目
主要科目
次要科目
科数网
首页
刷题
学习
VIP会员
赞助
组卷
集合
教材
VIP
写作
游客,
登录
注册
在线学习
高中数学
第十二章:概率与统计(高中)
独立检验★★★★★
最后
更新:
2026-01-09 15:50
查看:
165
次
反馈
能力测评
会员8.2元/月
赞助
独立检验★★★★★
独立检验;列联表
## 引入 本节先通过一个生活中的小例子来解释本章想说的内容,方便读者对本章由一个大致的了解。 独立检验其实可以用**生活里的“猜真相”场景**来理解——本质是“用证据反驳‘默认假设’,但要小心别冤枉人”。以下是最通俗的拆解: ## 一、怎么证明“这杯奶茶没加糖”? 假设你身体不好,不适宜喝太甜的东西,但是你怀疑奶茶店员工忘记了你的嘱托,还是给你加了糖(你想验证店员说的“没加糖”是不是真的),但是,店员在配置奶茶时你没法直接看店员的操作,只能 **尝一口(样本)** 来判断整杯奶茶(总体)的情况。 这时候你会怎么做? - 先假设“默认情况”:**这杯奶茶没加糖(原假设H₀)**——这是你要“挑战”的起点; - 然后尝一口:如果特别甜,你可能会怀疑“奶茶是真的加糖了”;如果味道很淡,你就会觉得“可能确实没加糖”。 但这里有个问题:**就算奶茶真的没加糖,也可能本身奶茶粉就具有甜性**——你不能因为一口甜就100%断定“加了糖”,得定个“**多甜才算真的加了糖**”的标准。 ## 二、假设检验的核心逻辑:“小概率事件不会随便发生” 回到奶茶的例子,我们可以把逻辑提炼成3步: ### 1. 先立个“靶子”:原假设(默认情况) 原假设就是“大家都默认的、不需要证明的事实”,比如: - 奶茶没加糖(H₀); - 新药和传统药效果一样(H₀); - 某班平均分等于年级平均分(H₀)。 它的作用是:**我们要“找证据推翻它”,而不是证明它**。 ### 2. 定个“犯错底线”:显著性水平(α) 你尝奶茶时,得先想:“我最多允许自己‘冤枉好人’的概率是多少?”——比如选5%(α=0.05): - 意思是:**如果奶茶真的没加糖(H₀为真),我尝一口发现‘特别甜’的概率只有5%,这种事几乎不会发生**。 如果这个概率超过了5%(比如尝20次有1次特别甜),你就不能轻易说“加了糖”——因为你可能是“冤枉”了没加糖的奶茶。 ### 3. 尝一口算“证据强度”:检验统计量和P值 你尝奶茶时,会用“甜度”来衡量样本和原假设的差异(这就是**检验统计量**)——比如用“甜度评分”(1-10分,1=超淡,10=超甜): - 如果原假设是“没加糖”,预期甜度是2分(奶茶毕竟不是纯净水,总会有点甜度的); - 你尝了一口,甜度是9分(差异很大),这时候要算**P值**:**“如果奶茶真的没加糖(H₀为真),我能尝到9分这么甜(或更甜)的概率有多大?”** 如果P值≤5%(比如P=0.01):说明“没加糖却尝到这么甜”是小概率事件,现在居然发生了——那更合理的结论是“奶茶加了糖”(拒绝原假设); 如果P值>5%(比如P=0.6):说明“没加糖却尝到这么甜”不算罕见,可能是你运气不好抽到甜的一口——那就“不拒绝原假设”(暂时认为没加糖),然后接受原假设,即没有加糖。 ## 独立检验 > **独立检验的核心思想是:小概率事件在一次模拟实验里,应该不发生的(比如$H_0$:假设彩票中奖是公平的。彩票中奖率为0.01%,也就是1万次才可能中奖1次), 而你去买彩票,买了100次中奖了3次(中奖率为3%),小概率事件发生了,那么我们就有理由怀疑你事先知道了号码或者彩票抽奖是不公平的,因此拒绝原假设“$H_0$:彩票是公平的”而接受备则假设“$H_1$:彩票是不公平的”**。 我们通过一个简单例子来理解独立检验的实际意义。在许多实际问题中,我们需要考察两个分类变量之间是否有关系。例如,考察患肺癌与吸烟之间是否有关系。 为了了解患肺癌与吸烟之间的关系,某医疗机构调查了其他条件都基本相同的 100 个人,调查结果如下表(表中 $X$ 表示"是否吸烟",$Y$ 表示"是否患肺癌")。 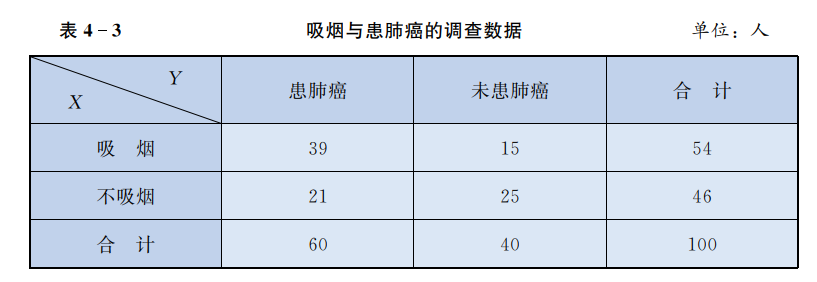{width=600px} 像上表这样,将两个分类变量进行交叉分类得到的频数分布表称为**列联表**;称 $X, Y$ 为**分类变量**,其中变量 $X$ 有两个变量值——"吸烟"和"不吸烟",变量 $Y$ 有两个变量值——"患肺癌"和"未患肺癌"。 由于所涉及的两个分类变量 $X, Y$ 均有两个变量值,所以称上表为 **$2 \times 2$ 列联表**. 从表 4-3 可以得出,在 54 个吸烟的人中有 39 人患肺癌,患者占 $39 / 54 \approx$ $72.22 \%$ ;在不吸烟的 46 人中,有 21 人患肺癌,患者占 $21 / 46 \approx 45.65 \%$ 。吸烟者中患肺癌的比例比不吸烟者中患肺癌的比例高出约 $$ 72.22-45.65=26.57 \text { (个百分点). } $$ 这种差异似乎已经说明吸烟与患肺癌有很大关系。但仔细想想,由于这 100 人是随机选取的,会不会是由于随机抽样的误差,使得所抽取的 60 名肺癌患者中碰到了较多的吸烟者,而在 40 名未患肺癌者中碰到了较多的不吸烟者?这样也可能导致吸烟者中肺癌患者的比例比不吸烟者中肺癌患者的比例高。 于是,我们还需进一步用统计方法来检验,因为单凭随机抽样的误差可能还不足以造成如此大的差异。 为了讨论的方便我们引人以下记号: 变量 $X: A=$ 吸烟, $\bar{A}=$ 不吸烟; 变量 $Y: B=$ 患肺癌, $\bar{B}=$ 未患肺癌. 我们将表 4-3 中的数字用字母代替得到如下列联表: {width=600px} 在本案例中, $$ \begin{aligned} & a=39, b=15, c=21, d=25 \\ & n=a+b+c+d=100 \\ & a+b=54 \\ & c+d=46 \\ & a+c=60 \\ & b+d=40 \\ \end{aligned} $$ 为分析 $X, Y$ 是否有关系,我们先提出假设 > **$H_0: X, Y$ 之间没有关系(独立)** , 也就是假设"吸烟 $(A)$"与"患肺癌 $(B)$"独立.这时 $A$ 与 $B$ 独立, $\bar{A}$ 与 $B$ 独立,$A$与 $\bar{B}$ 独立, $\bar{A}$ 与 $\bar{B}$ 独立. 于是 $P(A \cap B)=P(A) P(B)$ 吸烟和患肺癌, $P(\bar{A} \cap B)=P(\bar{A}) P(B)$ 不吸烟和患肺癌, $P(A \cap \bar{B})=P(A) P(\bar{B})$ 吸烟和不患肺癌, $P(\bar{A} \cap \bar{B})=P(\bar{A}) P(\bar{B})$ 不吸烟和不患肺癌 根据概率与频率的关系,知道 $P(A \cap B)$ 的估计值为 $p_{A B}=\frac{a}{n}=0.39$, $P(\bar{A} \cap B)$的估计值为 $p_{\bar{A} B}=\frac{c}{n}=0.21$, $P(A \cap \bar{ B })$ 的估计值为 $p_{A \bar{B}}=\frac{b}{n}=0.15$, $P(\bar{A} \cap \bar{B})$ 的估计值为 $p_{\bar{A} \bar{B}}=\frac{d}{n}=0.25$ . 又 $P(A)$ 的估计值为 $p_A=\frac{a+b}{n}=0.54$, $P(\bar{A})$的估计值为 $p_\bar{A}=\frac{c+d}{n}=0.46$ , $P(B)$ 的估计值为 $p_B=\frac{a+c}{n}=0.6$, $P(\bar{B})$ 的估计值为 $p_\bar{B}=\frac{b+d}{n}=0.4$ . 因为假设 $X, Y$ 独立,所以 $\mu_{A B}=\left|p_{A B}-p_A p_B\right|$ $\mu_{\bar{A} B}=\left|p_{\bar{A} B}-p_\bar{A} p_B\right|$ $\mu_{A \bar{B}}=$ $\left|p_{A \bar{B}}-p_A p_\bar{B}\right|$ $\mu_{\bar{A} \bar{B}}=\left|p_{\bar{A} \bar{B}}-p_\bar{A} p_\bar{B}\right|$ 都相应比较小. 我们用 $\chi^2$(读作"卡方")表示 $\mu_{A B}, \mu_{\bar{A} B}, \mu_{A \bar{B}}, \mu_{\bar{A} \bar{B}}$ 的总体大小,记 $$ \begin{aligned} \chi^2 & =\dfrac{n \mu_{A B}^2}{p_A p_B}+\dfrac{n \mu_{\bar{A} B}^2}{p_\bar{A} p_B}+\dfrac{n \mu_{A \bar{B}}^2
其他版本
【概率论与数理统计】附录5:卡方分布表
【概率论与数理统计】检验的基本原理
【概率论与数理统计】卡方分布
免费注册看余下 70%
非VIP会员每天5篇文章,开通VIP 无限制查看
《高等数学》难点解析
高数教程
泰勒公式
切线与法线
切平面与法平面
驻点·拐点·极值点·零点
间断点
渐进线
瑕积分
欧拉方程
伯努利方程
Abel 收敛定理
偏导数的几何意义
偏导数的几何意义
梯度
数量场与向量场
多元函数极值
拉格朗日算子
通量与散度
环流量与旋度
格林公式
高斯公式
斯托克斯公式
三大公式比较
傅里叶级数
极坐标微元
点法式方程
变上限定积分
X型计算面积
Y型计算面积
微分的意义
渐近线
间断点
y''+py'+qy=f(x)方程
高斯
黎曼
傅里叶变换(复数)
拉普拉斯变换(复数)
高等数学测评
函数与极限
一元函数微分学
一元函数积分学
微分方程
空间向量与代数
多元微分学
多元积分学
无穷级数
《线性代数》难点解析
线代教程
近世代数对数学的整体思考
线性的意义
矩阵乘法(列视角)
矩阵乘法(行视角)
矩阵左乘
矩阵右乘
逆矩阵求解方程组
阶梯形矩阵的求法
方程组解的判定
四阶行列式的计算
线性变换的意义
线性空间
向量组的等价
线性空间的几何意义
基础解系的求法
施密特正交化
特征值与特征向量的意义
矩阵相似的几何意义
矩阵可对角化的理解
秩的意义(向量版)
秩的意义(方程版)
二次型的意义
线性代数测评
行列式
矩阵
向量空间
《概率论与数理统计》难点解析
概率教程
置信区间与上a分位数
概率中的“取”与“放”
贝叶斯公式
全概率公式
泊松分布
指数分布
伽玛分布
二维密度图的意义
卷积的意义
相关系数的意义
k阶矩是与矩母函数
卡方分布的作用
单正态区间估计理解
假设检验理解
切比雪夫不等式
中心极限定理
概率统计测评
事件与概率
一维随机变量与事件
多维随机变量与事件
随机变量的数字特征
大数定律与中心极限定理
统计量与抽样分布
参数估计
假设检验
上一篇:
一元线性回归模型的应用
下一篇:
阅读:蒙特卡洛算法
本文对您是否有用?
有用
(
0
)
无用
(
0
)
更多
学习首页
数学试卷
同步训练
投稿
会议预约系统
数学公式
关于
Mathhub
赞助我们
科数网是专业专业的数学网站 版权所有
本站部分教程采用AI制作,请读者自行判别内容是否一定准确
如果页面无法显示请联系 18155261033 或 983506039@qq.com