切换科目
重点科目
主要科目
次要科目
科数网
首页
刷题
学习
VIP会员
赞助
组卷
集合
教材
VIP
写作
游客,
登录
注册
在线学习
概率论与数理统计
第七篇 参数估计
点估计(极大似然估计★★★★★)
最后
更新:
2026-01-04 13:28
查看:
423
次
反馈
能力测评
会员8.2元/月
赞助
点估计(极大似然估计★★★★★)
### 引言 **引例1:** 设有外形完全相同的**两个箱子**,甲箱中有 99 个白球和 1 个黑球,乙箱中有 99 个黑球和 1 个白球,今随机地抽取一箱,并,结果取得白球,问这球是从哪一个箱子中取出? {width=400px} 解 不管是哪一个箱子,从箱子中任取一球都有两个可能的结果:$A$ 表示"取出白球",$B$ 表示"取出黑球"。如果我们取出的是甲箱,则 $A$ 发生的概率为 0.99 ,而如果取出的是乙箱,则 $A$ 发生的概率为 0.01 .现在一次试验中结果 $A$ 发生了,人们的第一印象就是:"此白球 $(A)$ 最像从甲箱取出的",或者说,应该认为试验条件对结果 $A$ 出现有利,从而可以推断这球是从甲箱中取出的。这个推断很符合人们的经验事实,这里"最像"就是"最大似然"之意。这种想法常称为"最大似然原理"。 **引例2:** 想象一个场景:你是一个侦探,在一个房间里发现了一顶帽子。你知道这顶帽子可能属于三个人:张三、李四或王五,并且你知道他们各自戴帽子的概率(比如张三有80%的时间戴帽子,李四只有20%,王五从不戴)。现在,你看到了这顶帽子,那么你会最倾向于认为它是谁的?毫无疑问,你倾向张三的。 > 把这种思想用到点估计上就是:在已知样本观测结果的情况下,找到最有可能(概率最大)产生这个样本的参数值。简单来说,就是 **“让已知发生的事件概率最大”**。 ## 极大似然估计通俗理解 `例` 设袋中放有很多的白球和黑球,已知两种球的比例为1∶9,但不知道哪种颜色的球多,现从中有放回地抽取3次,每次一球,发现前两次为黑球,第三次为白球,试判断哪种颜色的球多. 解:根据抽取结果,我们的直观感觉是黑球多,下面给出理论依据. 设 $\theta$ 表示黑球所占比例,由题意知 $\theta$ 的值为0.9或0.1,设X表示每次抽球中黑球出现的次数,则X服从(0−1)分布,其分布律如下 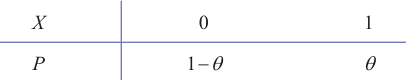 有放回地抽取 3 次,前两次为黑球,第三次为白球,相当于在总体 $X$ 中抽取了一组样本 $X_1, X_2, X_3$ ,样本观测值为 $X_1=1, X_2=1, X_3=0$ ,判断哪种颜色的球多,相当于在事件 $A=\left\{X_1=1, X_2=1, X_3=0\right\}$ 发生的前提下,判断 $\theta$ 的值是 0.9 还是 0.1. $$ P(A)=P\left\{X_1=1, X_2=1, X_3=0\right\}=P\left\{X_1=1\right\} P\left\{X_2=1\right\} P\left\{X_3=0\right\}=\theta^2(1-\theta) $$ 当 $\theta=0.9$ 时,$P(A)=0.9^2 \times 0.1=0.081$ ; 当 $\theta=0.1$ 时,$P(A)=0.1^2 \times 0.9=0.009$ . 根据最大似然估计法的基本原理,$\theta=0.9$ 应该有利于 $A=\left\{X_1=1, X_2=1, X_3=0\right\}$ 的发生,即黑球多. ### 引申1 假设车间送来一盒螺丝,他们认为产品都是合格的,但是做为质检部门的我却不这么认为,我们总是默认里面有不合格的,但是不合格有多少我们不知道(或者说不知道合格概率 $p$ 为多少),我们能做的只能抽查。 {width=300px} 现在我随机的有放回的从这盒螺丝抽取一个产品,然后记录他是否合格,一共抽查十次,假设随机变量为: $$ X=\text { "抽查10次合格产品的次数" } $$ 那么该随机变量服从 $p$ 未知的二项分布: $$ X \sim b(10, p) $$ 我们把螺丝抽查了10次,假设得到8个合格的,也就是得到了一个该二项分布的样本(此样本的容量为 1 ),要借此推断未知参数 $p$ 为多少。首先列出得到8次合格的概率: $$ \boxed{ P(X=8)=C_{10}^8 p^8(1-p)^2 ...(1) } $$ ①假如说 $p=0.7$ ,那么上述概率为: $$ P(X=8)=C_{10}^8 * 0.7^8 * (1-0.7)^2 \approx 0.23 $$ ②假如说 $p=0.8$ ,上述概率为: $$ P(X=8)=C_{10}^8 * 0.8^8 * (1-0.8)^2 \approx 0.30 $$ ③假如说 $p=0.9$ ,那么上述概率为: $$ P(X=8)=C_{10}^8 * 0.9^8 * (1-0.9)^2 \approx 0.19 $$ 根据最大似然的思想,$p=0.8$ 的可能性更大,所以应该认为 $p=0.8$ 更接近于事实,即产品合格率在 $80 \% $ 在上面计算过程中,可以看到所谓求最大似然的值,其实就是求函数(1)的最值(常数项可以忽略),设 $$ \boxed{ L(p)=p^8(1-p)^2 ...(2) } $$ 要求(2)的最值,有2个方法: **方法1** 只要对(2)求导并令导数为零即可,即 $$ L'= 2p^7(1-p)(4-5p)=0 ...(3) $$ 可得$p=0,p=1,p=0.8$ 舍去不可能的值,所以$p=0.8$时,似然函数取得最大值。 **方法2** 对(2)两边取对数,这样会把右侧的**乘法变成加法** $$ Ln L= 8 \ln p + 2 \ln(1-p) ...(4) $$ 再求导并令导数为零得 $$ \frac{8}{p}-\frac{2}{1-p}=0 $$ 可以解的 $p=0.8$ 假设车间说他们合格率为90%,但是我就可以利用数据来证明他们产品最大可能性为合格率为 80% ### 引申2 对于连续型的,以均匀分布为例,假设雨点均匀落在 $[0,a]$ 之间,那么他的密度函数是 (注意:a未知,是我们要求的变量) $$ p(x)= \left\{ \begin{array}{l} \frac{1}{a}, \quad x \in a \\ 0 , \quad else \end{array} \right. $$ 现在观察雨点实际落的位置是 $0.1,0.4,0.4,0.3,0.6$,怎么估算$a$的值?因为对连续性而言,每点的密度概率都是0的,为此,在这种情况下,我们使用联合概率密度函数计算他的最值,即 $$ L(a)=\frac{1}{a^n} $$ 上面求$L(a)$的最大值,如果不可微,直接求是计算不了的,此时需要转换思维。 其实取 $a$为 $\max \{x_1,x_2,..x_n\}$,具体参考下面视频解释。 下面视频介绍了取数的意义(视频来B站《小崔说数》) <video width=600px height="500px"; controls> <source src="/uploads/2025-09/siranguji.mp4" type="video/mp4" /> </video> ## 似然函数 在极大似然估计法中,最关键的问题是如何求得似然函数(定义之后给出),有了似然函数,问题就简单了,下面分两种情形来介绍似然函数. ### (1)离散型总体的似然函数 设总体 $X$ 的概率分布为 $$ P\{X=x\}=p(x, \theta) $$ 其中 $\theta$ 为末知参数.如果 $X_1, X_2, \cdots, X_n$ 是取自总体 $X$ 的样本,样本的观察值为 $x_1, x_2, \cdots, x_n$ ,则样本的联合分布律为 $$ \begin{aligned} P\left\{X_1=x_1, X_2=x_2, X_n=x_n\right\} & =P\left\{X_1=x_1\right\} P\left\{X_2=x_2\right\} \cdots P\left\{X_n=x_n\right\} \\ & =p\left(x_1, \theta\right) p\left(x_2, \theta\right) \cdots p\left(x_n, \theta\right) \\ & =\prod_{i=1}^n p\left(x_i, \theta\right) . \end{aligned} $$ 将 $\prod_{i=1}^n p\left(x_i, \theta\right)$ 视为参数 $\theta$ 的函数,记为 $L(\theta)=L\left(x_1, x_2, \cdots, x_n, \theta\right)=\prod_{i=1}^n p\left(x_i, \theta\right)$ ,并称其为似然函数. ### (2)连续型总体的似然函数 设总体 $X$ 的概率密度为 $f(x, \theta)$ ,其中 $\theta$ 为末知参数,此时定义似然函数 $$ L(\theta)=L\left(x_1, x_2, \cdots, x_n, \theta\right)=\prod_{i=1}^n f\left(x_i, \theta\right) . $$ 似然函数 $L(\theta)$ 的值的大小意味着该样本值出现的可能性的大小,在已得到样本值 $x_1, x_2, \cdots, x_n$的情况下,则应该选择使 $L(\theta)$ 达到最大值的那个 $\theta$ 作为 $\theta$ 的估计 $\hat{\theta}$ .这种求点估计的方法称为最大似然估计法.综合以上分析,下面给出最大似然估计的定义. > 注意:在这个定义里,总体的概率分布由**未知参数** $\theta$ 决定,这里的 $\theta$ 可以是单个参数,也可以是参数向量。例如:正态分布 $N(\mu,\sigma^2)$ 的未知参数是 $\theta=(\mu,\sigma^2)$ 两个参数;二项分布 $B(n,p)$ 的未知参数是 $\theta=p$是一个参数。 ## 极大似然估计定义 设总体有分布 $f\left(X ; \theta_1, \cdots, \theta_k\right), X_1, \cdots, X_n$ 为自这总体中抽出的样本, 则样本 $\left(X_1, \cdots, X_n\right)$ 的分布 (即其概率密度函数或概率函数)为$f\left(X_1 ; \theta_1, \cdots, \theta_k\right) f\left(X_2 ; \theta_1, \cdots, \theta_k\right) \cdots f\left(X_n ; \theta_1, \cdots, \theta_k\right)$ 记之为 $L\left(X_1, \cdots, X_n ; \theta_1, \cdots, \theta_k\right)$ 。英文叫做Maximum Likelihood Estimation, MLE 固定 $\theta_1, \cdots, \theta_k$ 而看作是 $X_1, \cdots, X_n$ 的函数时, $L$ 是一个概率密度函数或概率函数,我们可以这样理解: 若 $L\left(Y_1, \cdots, Y_n ; \theta_1, \cdots, \theta_k\right)$ $>L\left(X_1, \cdots, X_n ; \theta_1, \cdots, \theta_k\right)$, 则在观察时出现 $\left(Y_1, \cdots, Y_n\right)$ 这个点的可能性, 要比出现 $\left(X_1, \cdots, X_n\right)$ 这个点的可能性大. 把这件事反过来说,可以这样想:当已观察到 $X_1, \cdots, X_n$ 时,若 $L\left(X_1, \cdots, X_n\right.$ ; $\left.\theta_1^{\prime}, \cdots, \theta_k^{\prime}\right) > L\left(X_1, \cdots, X_n ; \theta_1^{\prime \prime}, \cdots, \theta_k^{\prime \prime}\right)$ ,则被估计的参数 $\left(\theta_1\right.$, $\cd
免费注册 查看余下70%
《高等数学》难点解析
高数教程
泰勒公式
切线与法线
切平面与法平面
驻点·拐点·极值点·零点
间断点
渐进线
瑕积分
欧拉方程
伯努利方程
Abel 收敛定理
偏导数的几何意义
偏导数的几何意义
梯度
数量场与向量场
多元函数极值
拉格朗日算子
通量与散度
环流量与旋度
格林公式
高斯公式
斯托克斯公式
三大公式比较
傅里叶级数
极坐标微元
点法式方程
变上限定积分
X型计算面积
Y型计算面积
微分的意义
渐近线
间断点
y''+py'+qy=f(x)方程
高斯
黎曼
傅里叶变换(复数)
拉普拉斯变换(复数)
高等数学测评
函数与极限
一元函数微分学
一元函数积分学
微分方程
空间向量与代数
多元微分学
多元积分学
无穷级数
《线性代数》难点解析
线代教程
近世代数对数学的整体思考
线性的意义
矩阵乘法(列视角)
矩阵乘法(行视角)
矩阵左乘
矩阵右乘
逆矩阵求解方程组
阶梯形矩阵的求法
方程组解的判定
四阶行列式的计算
线性变换的意义
线性空间
向量组的等价
线性空间的几何意义
基础解系的求法
施密特正交化
特征值与特征向量的意义
矩阵相似的几何意义
矩阵可对角化的理解
秩的意义(向量版)
秩的意义(方程版)
二次型的意义
线性代数测评
行列式
矩阵
向量空间
《概率论与数理统计》难点解析
概率教程
置信区间与上a分位数
概率中的“取”与“放”
贝叶斯公式
全概率公式
泊松分布
指数分布
伽玛分布
二维密度图的意义
卷积的意义
相关系数的意义
k阶矩是与矩母函数
卡方分布的作用
单正态区间估计理解
假设检验理解
切比雪夫不等式
中心极限定理
概率统计测评
事件与概率
一维随机变量与事件
多维随机变量与事件
随机变量的数字特征
大数定律与中心极限定理
统计量与抽样分布
参数估计
假设检验
上一篇:
点估计(矩估计法)
下一篇:
无偏性
本文对您是否有用?
有用
(
0
)
无用
(
0
)
学习首页
数学试卷
同步训练
投稿
会议预约系统
数学公式
关于
Mathhub
赞助我们
科数网是专业专业的数学网站 版权所有
本站部分教程采用AI制作,请读者自行判别内容是否一定准确
如果页面无法显示请联系 18155261033 或 983506039@qq.com