切换科目
重点科目
主要科目
次要科目
科数网
首页
刷题
学习
VIP会员
赞助
组卷
集合
教材
VIP
写作
游客,
登录
注册
在线学习
概率论与数理统计
第二篇 一维随机变量及其分布
连续型(伽马分布garmma)
最后
更新:
2025-12-21 10:58
查看:
1312
次
反馈
能力测评
会员8.2元/月
赞助
连续型(伽马分布garmma)
伽马分布;gamma
> 注:在概率论里,和连续分布相关的基本上都和“时间”相关,因为时间是连续的。泊松过程的三个重要分布在概率论和随机过程理论中经常出现,它们分别是:**[泊松分布](https://kb.kmath.cn/kbase/detail.aspx?id=527)**(Poisson Distribution):描述固定时间内发生事件的数量。**[指数分布](https://kb.kmath.cn/kbase/detail.aspx?id=531)**(Exponential Distribution):描述事件间隔时间的分布。**[伽马分布](https://kb.kmath.cn/kbase/detail.aspx?id=960)**(Gamma Distribution):描述多个事件发生时间的分布。点击他们的分布链接可以了解三者之间的区别和联系。 ## 伽马分布 **提示:在阅读本文前,建议已经了解了[泊松分布](https://kb.kmath.cn/kbase/detail.aspx?id=527)和[指数分布](https://kb.kmath.cn/kbase/detail.aspx?id=531)** 若随机变量 $X$ 的概率密度函数为: $$ \boxed{ f(x; \alpha, \beta) = \frac{1}{\beta^\alpha \, \Gamma(\alpha)} \, x^{\alpha-1} e^{-x/\beta}, \quad x > 0 ...(1) } $$ 其中: - $\alpha > 0$ 称为**形状参数**(shape parameter) - $\beta > 0$ 称为**尺度参数**(scale parameter) - $\Gamma(\alpha)$ 是**伽马函数**,定义为: $$ \Gamma(\alpha) = \int_0^\infty t^{\alpha-1} e^{-t} \, dt $$ 且 $\Gamma(n) = (n-1)!$ 当 $n$ 为正整数。 则称 $X$ 服从**伽马分布**. ### 参数化形式 有时教材会用另一种参数化(速率参数 $\lambda = 1/\beta$) 来定义伽马分布: $$ \boxed{ f(x; \alpha, \lambda) = \frac{\lambda^\alpha}{\Gamma(\alpha)} \, x^{\alpha-1} e^{-\lambda x}, \quad x > 0 ...(2) } $$ 此时 $\mathbb{E}[X] = \alpha / \lambda$,$\mathrm{Var}(X) = \alpha / \lambda^2$。 注意: 第一种参数化($\beta$):均值 $\alpha\beta$,方差 $\alpha\beta^2$ 第二种参数化($\lambda$):均值 $\alpha/\lambda$,方差 $\alpha/\lambda^2$ > **对于初次接触伽玛分布的同学,可能会被伽玛分布的密度函数吓跑,感觉太复杂了,请注意:正像正态分布里有$\sqrt{2 \pi}$一样,伽玛分布之所以带 $\Gamma(\alpha)$ 主要是为了让分布函数的值为1,用来平衡积分的值,我们只要抓住核心关键参数即可** 伽马分布的密度函数图像 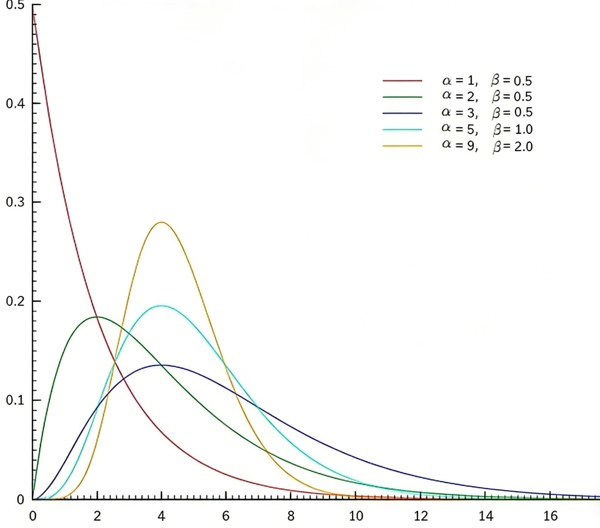{width=400px} ## 伽玛函数 在理解伽玛分布前,先介绍一下伽玛函数,顾名思义,看到伽玛分布,他一定和伽玛函数有光,伽玛函数的定义是: $$ \Gamma(\alpha)=\int_0^{\infty} x^{\alpha-1} \mathrm{e}^{-x} \mathrm{~d} x $$ 这是一个广义积分,当您第一次看到伽玛函数时,你有没有想过为什么要创造这样一个看起来很复杂又无规律的积分函数?其实伽玛函数并不是凭空产生的。 伽玛函数的理由来自函数图像的绘图。在初中我们学过“描点”绘图,比如要绘出$y=x^2$的图像,其中$x$是实数,我们很容易想到,把实数$x$用自然数$n$代替,然后取$n=-2,-1,0,1,2$ 可以得到5个点,把这5个点用曲线连接起来,这就是$y=n^2$图像 如下 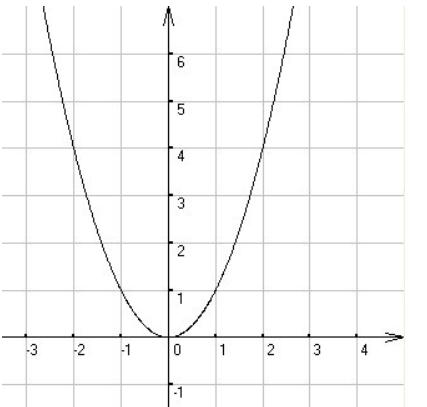{width=300px} 然后我们就想当然的认为$y=x^2$和$y=n^2$长相类似,后者就是前者的粗略版。 有了这个想法,我们现在要问一个问题:$y=x!$的图像是多少(x!表示$x$的阶乘)(点击查看[阶乘](http://kb.kmath.cn/kbase/detail.aspx?id=200)定义 ) 我们已经知道$5!=5*4*3*2*1, 4!=4*3*2*1,... 1!=1$ 既然已经知道$n!$得值,那么把这些点连接起来,是不是就是$y=x!$的图形呢? 我们把问题在具体一点,那 $y=\frac{1}{2} !$ 是多少? 如果要验证我们的阶乘值,就要知道 $y=\frac{1}{2} !$ 得值,为此,数学家重要得到了一个伽玛函数,伽玛函数有一个递推公式 $\Gamma(s+1)=s \Gamma(s)(s>0)$ ,现在我们已经知道 $\Gamma\left(\frac{1}{2}\right)=\sqrt{\pi}$ 而至于 $y=n !$ 的图形,也就可以画出来了。不过这已经超出了初等数学的范畴。伽玛函数的推导已经在高等数学里介绍过,详见 [高等数学伽玛函数教程](https://kb.kmath.cn/kbase/detail.aspx?id=1456) > **核心结论来了:伽玛函数可以理解为阶乘函数。他把阶乘的定义域从正整数扩展到了实数** 进一步的,一说到阶乘,你想到了什么?当然是排列组合了,在一开始的[排列组合](https://kb.kmath.cn/kbase/detail.aspx?id=3394) 会遇到大量阶乘运算,但是传统的阶乘都是正整数运算,伽玛函数相当于把定义域从正整数扩展到了整个实数范围内。 现在我们捋一捋其中的逻辑关系: > **排列组合 $\Leftrightarrow$ 阶乘运算 $\Leftrightarrow$ 伽玛函数** 所以,阶乘运算相当于桥梁,联系起了 “排列组合”和“伽玛函数”的内在关系。 也因此,你会在概率论的密度函数里,会有大量的伽玛函数出现。 理解了伽玛函数后,就可以引入伽玛分布了。 ## 为什么要引入伽玛分布 在理解Gamma分布前,让我们思考以下几个问题: ``` 1.为什么我们要发明Gamma分布?(也就是说,为什么这个分布会存在?) 2.什么时候应该用Gamma分布来做模型? ``` **我们为什么要发明Gamma分布?** 答案:为了预测未来事件发生前的等待时间。 嗯?难道这不是指数分布的研究的问题? 那么,指数分布和Gamma分布的区别是什么呢? > **指数分布描述的是独立事件的等待时间。而Gamma分布描述的是直到 k 个事件发生时的等待时间** 简单的来说,指数分布解决的问题是“要等到一个随机事件发生,需要经历多久时间”,伽玛分布解决的问题是“要等到 k 个随机事件都发生,需要经历多久时间” 下面列出了泊松分布、指数分布、伽马分布的应用场景。 **泊松分布**:主要预测单位时间内事件发生的平均次数。 例如医院每天接生10个婴儿,预测下一天接生1个婴儿,2个婴儿,10个婴儿,100个婴儿的概率是多少,这是泊松分布的目的。 **指数分布**:主要预测描述某个事件发生之前,我们需要等待的时间长度, 比如公交车每2个小时来一班公交车,即平均每小时发生 0.5 次事件。我们想知道下一班公交车在 10分钟内到来的概率,在20分钟内到来的概率,在1小时内到来的概率,在1天内到来的概率。这就是指数分布的目的。 **伽马分布**:预测多个时间等待的概率, 比如奶茶店的奶茶制作时间 $X$(单位:分钟)服从伽马分布 $X \sim \text{Gamma}(\alpha=2, \beta=3) $,其中: 形状参数 $ \alpha=2 $(可理解为“需要完成2个独立步骤”,比如泡茶+加料);速率参数 $ \beta=3$(可理解为“每步骤平均速率3次/分钟”,速率越大,完成越快)。我们要计算制作一杯奶茶不超过1分钟的概率,不超过2分钟的概率,不超过10分钟的概率,这就是伽马分布的目的 ## 推导伽玛分布的密度函数PDF 在指数分布中,我们从泊松过程推导出了指数分布的PDF(详见[此处](https://kb.kmath.cn/kbase/detail.aspx?id=531))。 要很好地理解Gamma分布,需要很好地理解它们。我们的学习顺序应该是:1.泊松分布,2.指数分布,3.gamma分布。 Gamma分布的PDF的推导与指数分布PDF的推导非常相似,除了一点--它是到第 k 个事件的等待时间,而不是第1个事件。 > $T$ :到第 $k$ 个事件的等待时间的随机变量(这是感兴趣的随机变量),其中事件的到达是由速率为 $\lambda$ 的泊松过程建模的。 $k$ :伽马的第一个参数,所等待的事件发生的次数。 $\lambda$ : Gamma的第二个参数,遵循泊松过程的事件发生速率。 $P(T>t)$ :到第 $k$ 个事件的等待时间大于 $t$ 个时间单位的概率。 $P(X=k |$ 在 $t$ 时间范围内 $)$ :在 $t$ 个时间单位内发生 $k$ 个事件的泊松概率。 上面预订了参数,现在看看怎么推导出伽玛分布的密度函数PDF。要得到密度函数需要先得到伽玛分布的分布函数CDF,然后对CDF微分就是密度函数。 分布函数$CDF$: $$ \begin{aligned} P(T \leq t) & =1-P(T>t) \\ & =1-P(0,1,2, \ldots K-1 \text { 事件发生在 }[0, t]) \\ & =1-\sum_{x=0}^{k-1} \frac{(\lambda t)^x e^{-\lamb
其他版本
【高等数学】伽玛函数
免费注册 查看余下70%
《高等数学》难点解析
高数教程
泰勒公式
切线与法线
切平面与法平面
驻点·拐点·极值点·零点
间断点
渐进线
瑕积分
欧拉方程
伯努利方程
Abel 收敛定理
偏导数的几何意义
偏导数的几何意义
梯度
数量场与向量场
多元函数极值
拉格朗日算子
通量与散度
环流量与旋度
格林公式
高斯公式
斯托克斯公式
三大公式比较
傅里叶级数
极坐标微元
点法式方程
变上限定积分
X型计算面积
Y型计算面积
微分的意义
渐近线
间断点
y''+py'+qy=f(x)方程
高斯
黎曼
傅里叶变换(复数)
拉普拉斯变换(复数)
高等数学测评
函数与极限
一元函数微分学
一元函数积分学
微分方程
空间向量与代数
多元微分学
多元积分学
无穷级数
《线性代数》难点解析
线代教程
近世代数对数学的整体思考
线性的意义
矩阵乘法(列视角)
矩阵乘法(行视角)
矩阵左乘
矩阵右乘
逆矩阵求解方程组
阶梯形矩阵的求法
方程组解的判定
四阶行列式的计算
线性变换的意义
线性空间
向量组的等价
线性空间的几何意义
基础解系的求法
施密特正交化
特征值与特征向量的意义
矩阵相似的几何意义
矩阵可对角化的理解
秩的意义(向量版)
秩的意义(方程版)
二次型的意义
线性代数测评
行列式
矩阵
向量空间
《概率论与数理统计》难点解析
概率教程
置信区间与上a分位数
概率中的“取”与“放”
贝叶斯公式
全概率公式
泊松分布
指数分布
伽玛分布
二维密度图的意义
卷积的意义
相关系数的意义
k阶矩是与矩母函数
卡方分布的作用
单正态区间估计理解
假设检验理解
切比雪夫不等式
中心极限定理
概率统计测评
事件与概率
一维随机变量与事件
多维随机变量与事件
随机变量的数字特征
大数定律与中心极限定理
统计量与抽样分布
参数估计
假设检验
上一篇:
阅读:正态分布的密度函数是如何推导出来?
下一篇:
连续型(贝塔Beta分布)
本文对您是否有用?
有用
(
0
)
无用
(
0
)
学习首页
数学试卷
同步训练
投稿
会议预约系统
数学公式
关于
Mathhub
赞助我们
科数网是专业专业的数学网站 版权所有
本站部分教程采用AI制作,请读者自行判别内容是否一定准确
如果页面无法显示请联系 18155261033 或 983506039@qq.com